 By
By
AWS Glue - ETL in the Cloud
Data Warehousing and Reporting are critical business functions. ETL (Extract, Transform and Load) plays a major role in making them possible. ETL "massages" the data, transforming and moving it between databases and systems. This enables Data Warehouses to use storage patterns conducive to fast and thorough retrieval.
If your business is looking to add or upgrade a data warehouse, who to trust with this responsibility? You want things to be super easy, wicked fast, and reliable. And you don't want to manage
- Using AWS Glue, an ETL service offering from Amazon
- Hiring Frankenstein to design, build and manage your custom implementation
We will examine

AWS Glue
According to AWS documentation, AWS Glue is "a fully managed extract, transform, and load (ETL) service that makes it easy for customers to prepare and load their data for analytics". Amazon offers a service for everything, don't they? From humans doing small tasks to Fargate, their container service, they offer it. Glue stands in as their ETL offering.
At a high level, it does the following:
- Collects information about your data sources. This includes where the data is stored, and the underlying schema of that data.
- Builds transformations between data sources. AWS Glue uses crawlers to inspect your various
schemas, and auto-generates the necessary code to transform from source to destination. Very Cool! - Manages Jobs to move the data, allowing for powerful scheduling and retry possibilities.
- Seamlessly integrates with other AWS Services, including S3 and Amazon Redshift Spectrum.

Frankenstein
Frankenstein was a bit more difficult to research. Inquiring around local taverns and inns, we heard frightening tales of a monster living in a nearby forest. After a long slog through a creepy marsh, we find him. He is sitting on a log, pondering the murky water beneath his feet.
Timidly, we laid out the problem we're looking to solve. Frankenstein appears not to listen. But after a pause, his face contorts with anger. "FRANKENSTEIN SMASH!@!@#" he bellows. Interesting. It would be nice to have someone solve this problem on our behalf. No muss, no fuss, they simply "Smash" it.
This may be a tougher decision than we imagined! Let's look at some of the features of both, and see if either stands out.
Comparison
Speed
ETL and Data Warehousing involve large datasets. Processing them in "real-time" is critical to getting the data when you need it. AWS Glue does not disappoint here. It leads the industry with massive computing
Frankenstein is a bit slow. He tends to plod towards destinations, in a meandering, unintentional path. He likes to tear things down along the way, which slows him even further.
AWS Glue takes the Speed category.
Hardware
ETL and Data Warehousing requires big hardware to digest all that information. AWS Glue sits on top of one of the largest cloud platforms on Earth. Their customers never have to worry about hardware. AWS handles OS upgrades, failed drives, or any other hardware bumps in the night. Additionally, you only pay for what you use. Capacity planning and
Frankenstein didn't appear to have any hardware ready. To get the project moving,
Hands down, AWS Glue offers the advantage when it comes to hardware.
Ease
While you want your ETL solution to be powerful, it can't be confusing. As a user, you want an intuitive, informative GUI to manage the system. AWS delivers here, with a web interface
It should be noted that if you go OFF the beaten path when setting up AWS Glue, you can quickly find yourself in a configuration swamp. Bizarre security errors that probably mean something to an AWS expert, but not to someone looking to quickly get up and running. It is advised to closely follow their tutorials, and ensure that all resources involved (S3, AWS Glue, etc) are in the same AWS region - this can cut down on the confusion.
Frankly, Frankenstein is the opposite of "easy". He can only communicate the simplest of ideas, usually in an aggressive manner. He never appears to understand your questions or ideas. He is easy to frustrate. At the slightest provocation, he will violently attack anything in his vicinity.
AWS Glue is easily the easiest of the two solutions.
Reliability
Having a top-notch ETL solution is useless if you can't depend on it. It needs to be up all the time, never strain under load, and grow with your data needs. AWS Glue has no problems with any of these requirements. Around the clock technical support and nearly 100% uptime SLAs allow you to sleep at night. When you need your data, AWS Glue will always deliver.
Frankenstein is unreliable. He'll more than likely scamper off into a forest as he will deliver your ETL solution. Unable to grasp basic concepts, Frankenstein is never someone to depend on.
AWS Glue handily wins this final category.
The Winner
It should be obvious to the reader that AWS Glue is hands down the better choice for your ETL solution. It allows you to focus on the functional needs of your solution, with "the pros" handling the implementation details. Only a complete mad scientist would opt for the Frankenstein route.
Example
Let's run through a short example demonstrating AWS Glue in action. Setting up a simple AWS Glue scenario is a straightforward exercise. Here is a small playbook:
Obtain the Data
For this example, we used StackOverflow's handy Data Explorer to query for
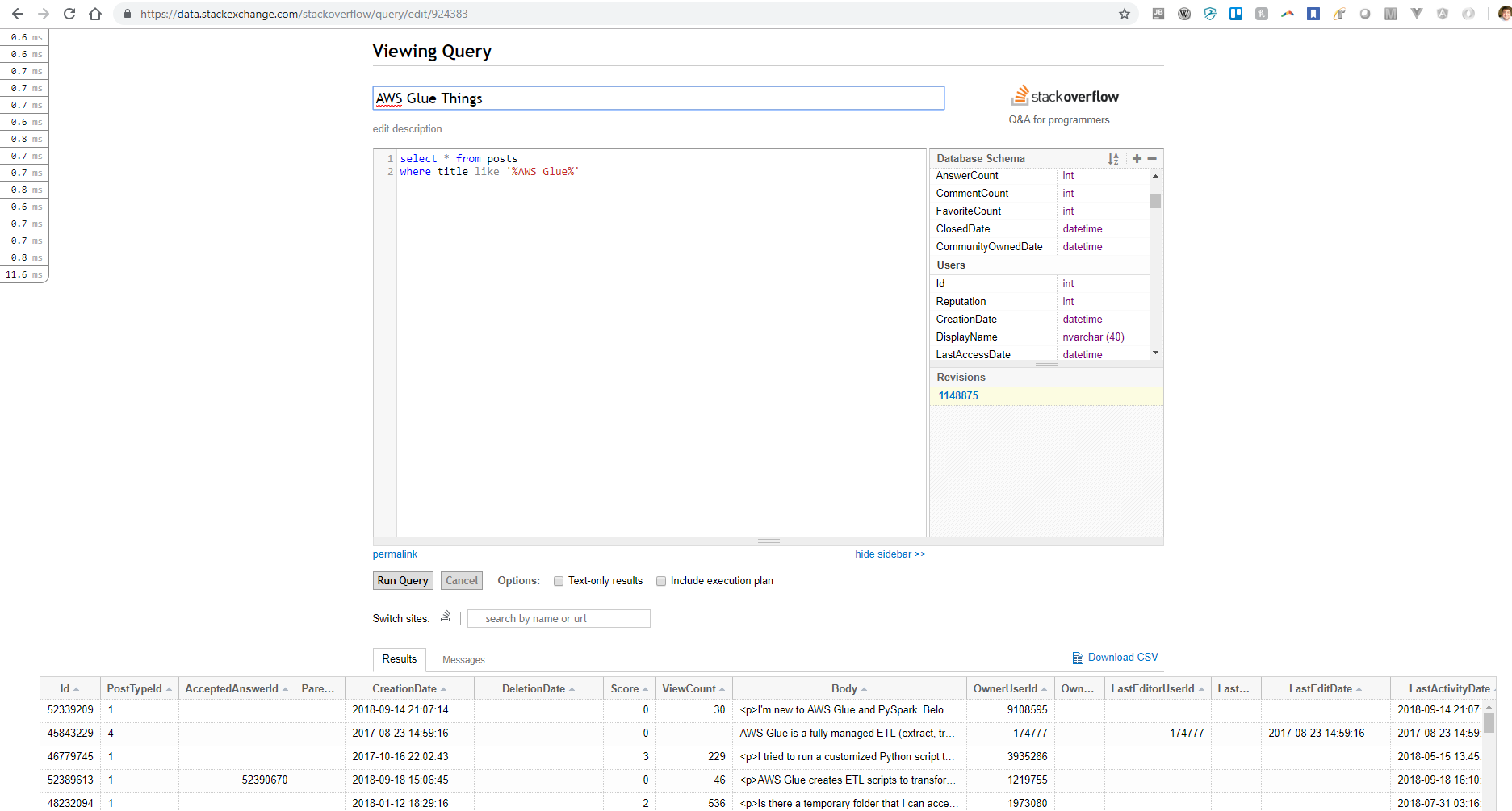
Upon completion, we download results to a CSV file, then upload them to AWS S3 storage. This will be the "source" dataset for the AWS Glue transformation.
Setup the Crawler
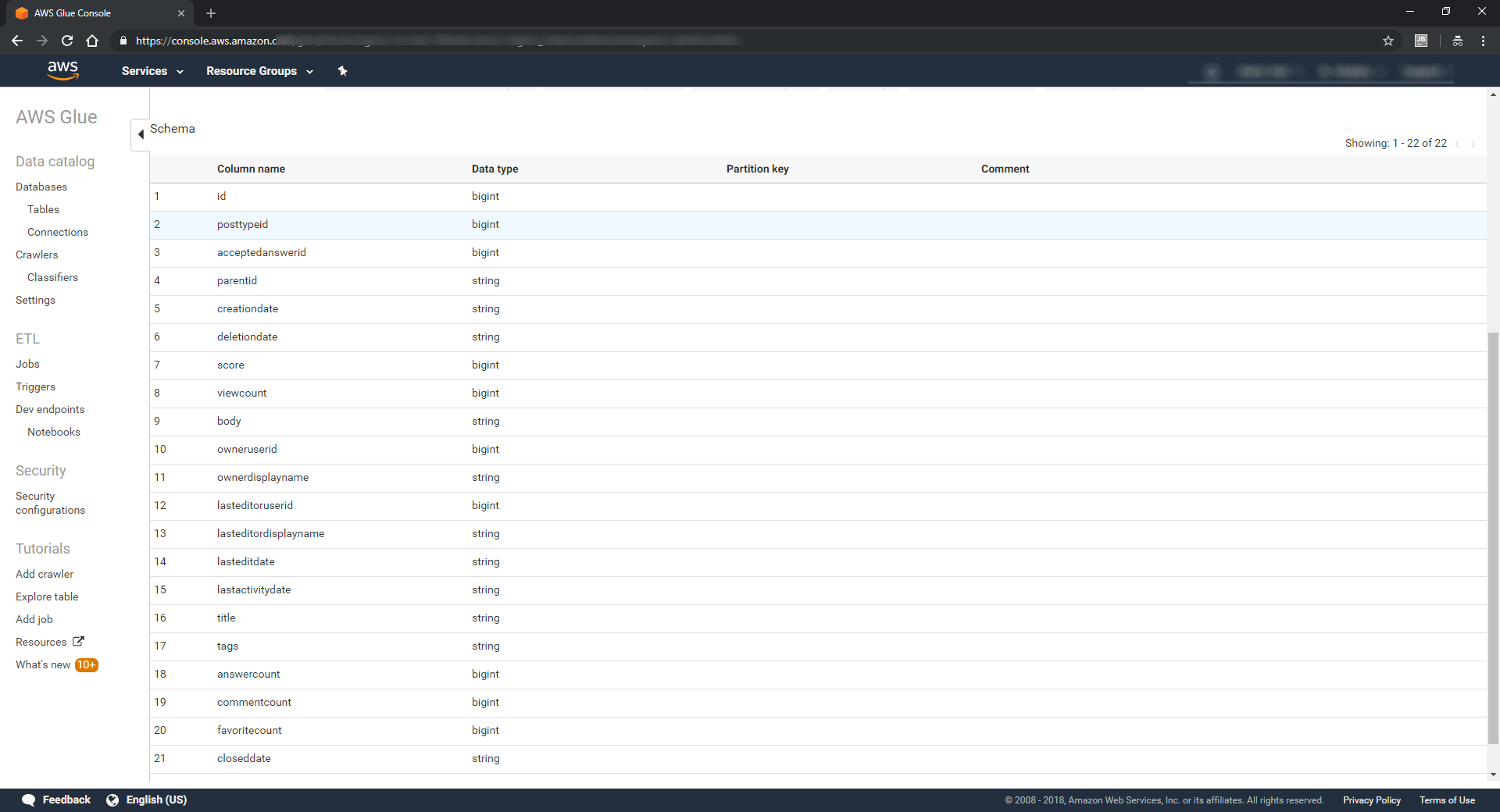
With data in hand, the next step is to point an AWS Glue Crawler at the data. The crawler will inspect the data and generate a schema describing what it finds. While AWS Glues supports custom classifiers for complicated data sets, our needs here are simple. Using the default values, the crawler produces schema completely describing our Stack Overflow data set:
Create a Job
With the schema in place, we can now create a Job. We don't need any fancy scheduling here, just need it to execute:
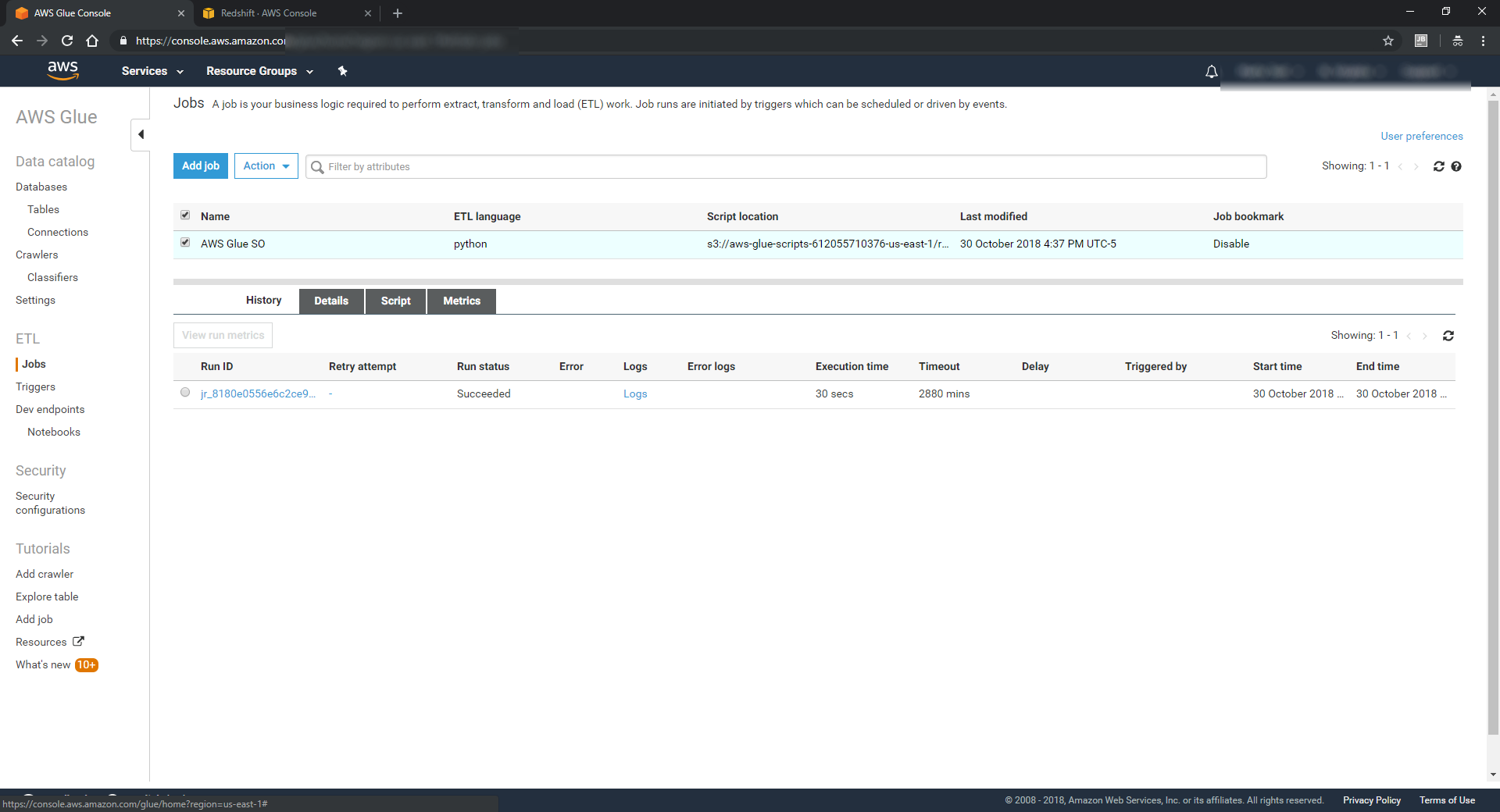
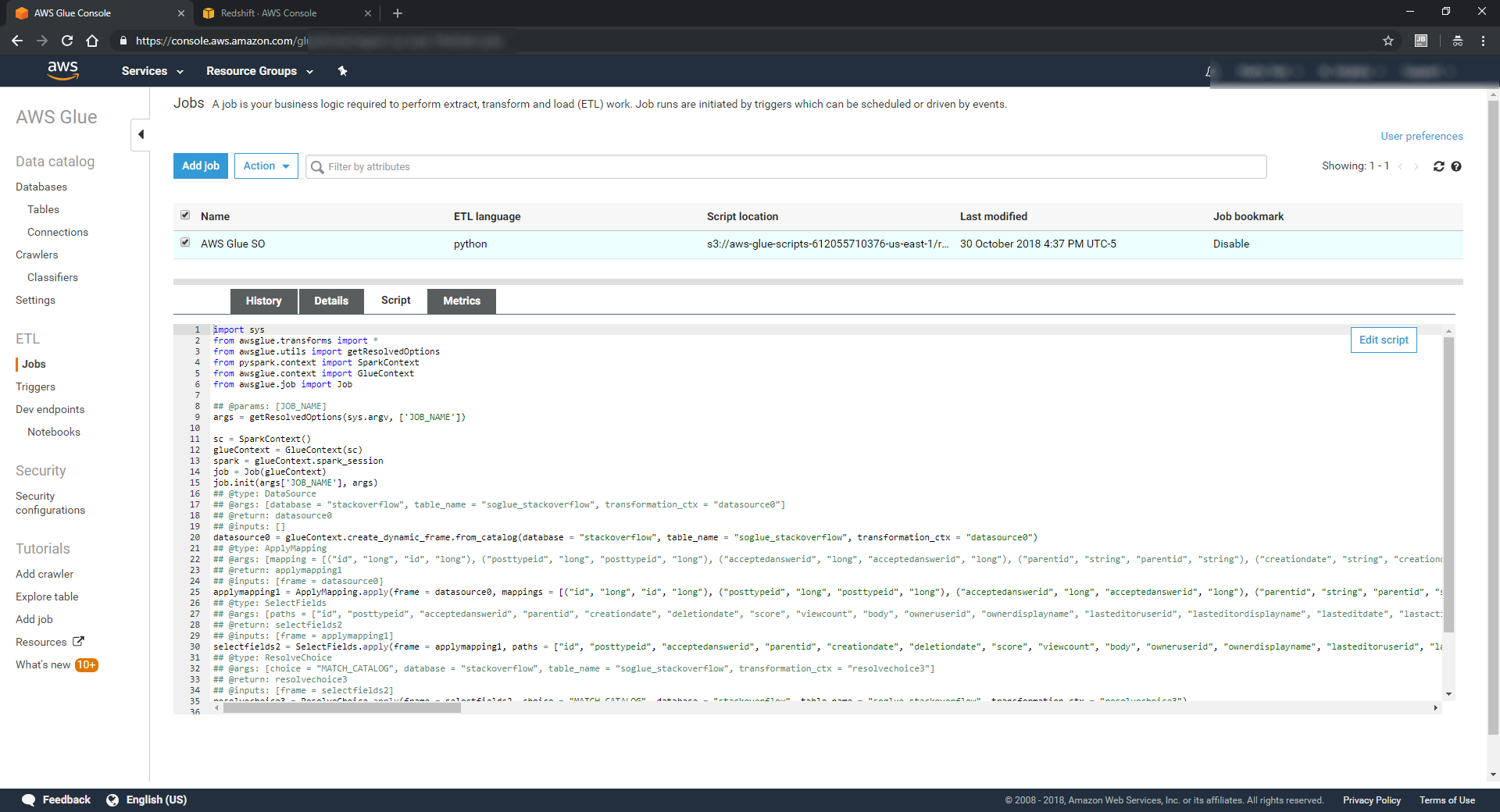
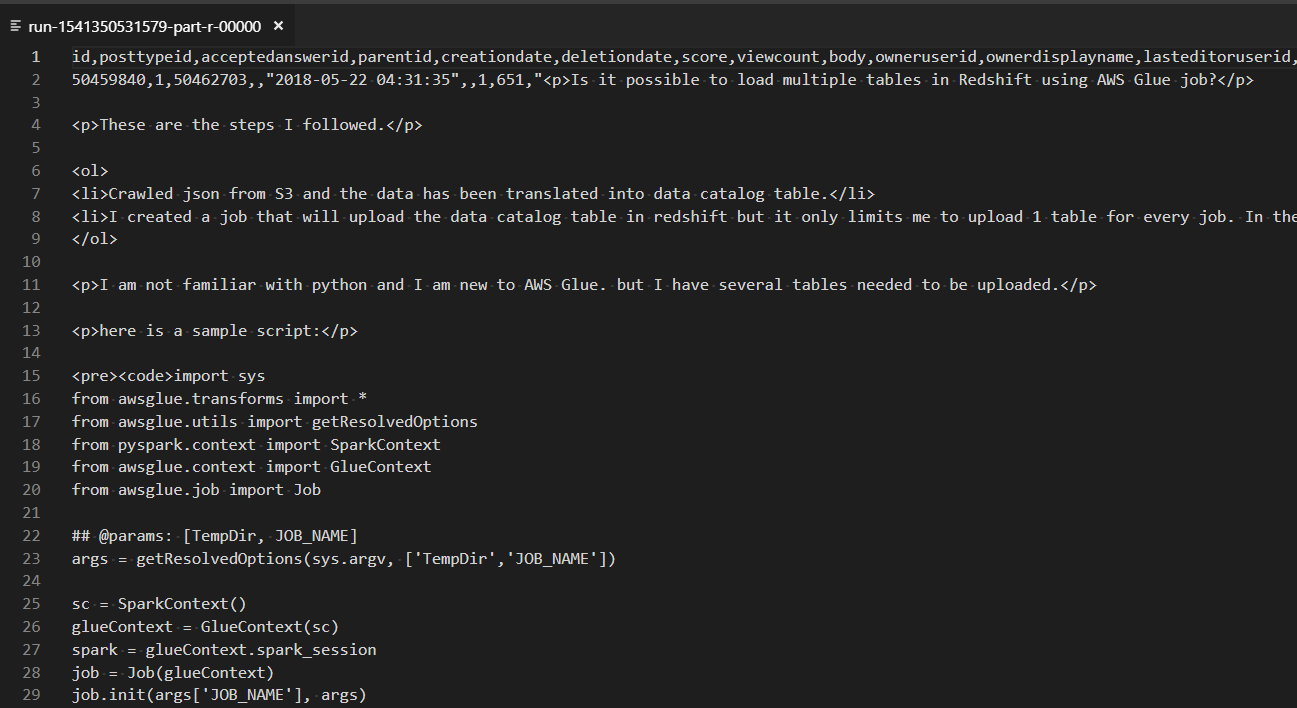
AWS Glue offers a GUI to define your input/output mappings, or you can just edit the script directly. For this simple example, I removed some of the output fields (so we're effectively reducing the number of columns in our output data set):
Output
Upon successful completion of our job, we now have a (transformed) data set in our S3 storage!
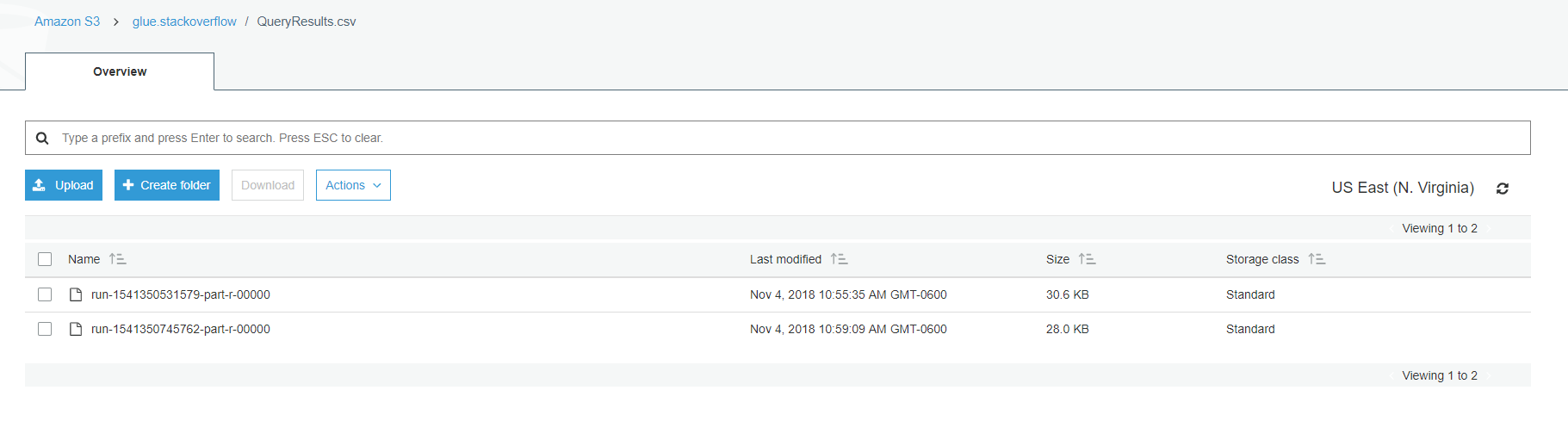
Expose Data Using SQL Bot
Now that we've got some healthy, transformed data, what next? In a
S3 Data Into AWS RedShift
AWS Redshift is a powerful Data Warehouse solution, and perfect for our needs. Using the "COPY" command, we can easily copy our data into AWS Redshift:
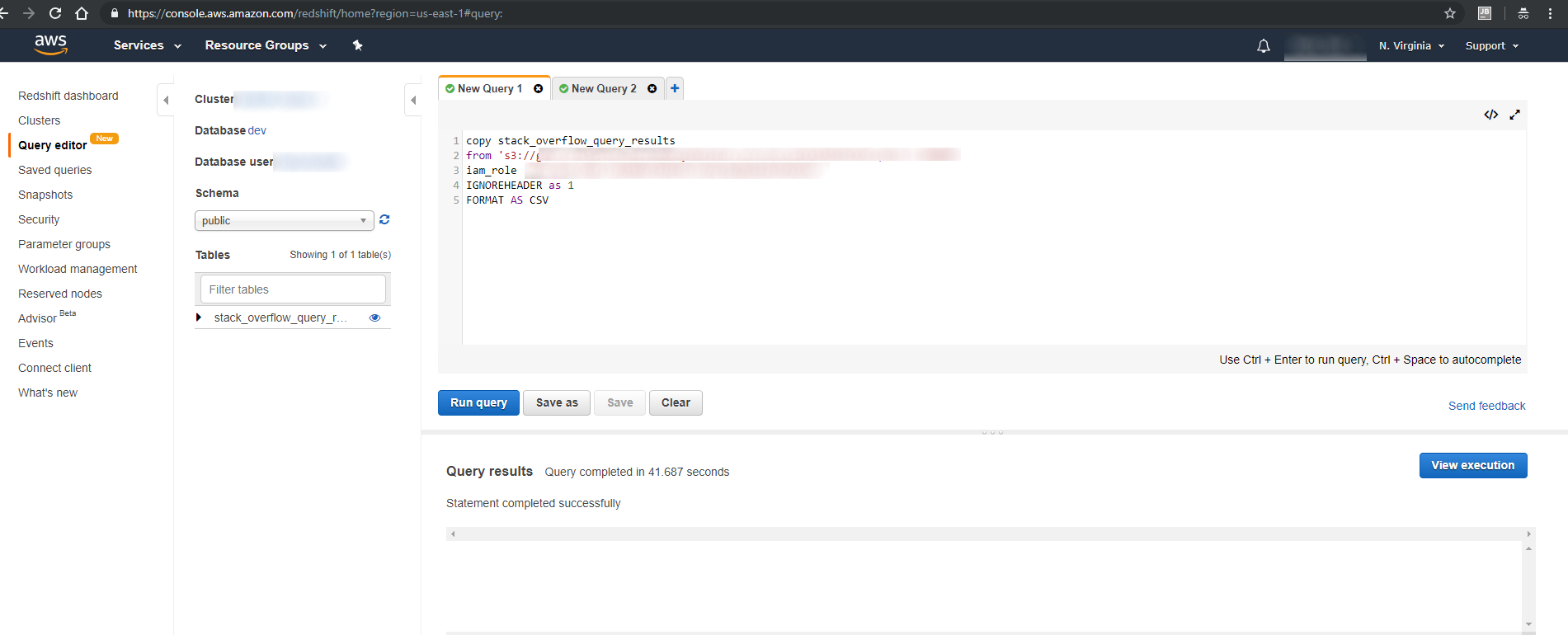
With this in place, our CSV data now becomes queryable.
Hook SQLBot to Redshift
Now time for the SQLBot magic! This is the easiest part of the exercise. First, add our Redshift Cluster as a connection within SQLBot:
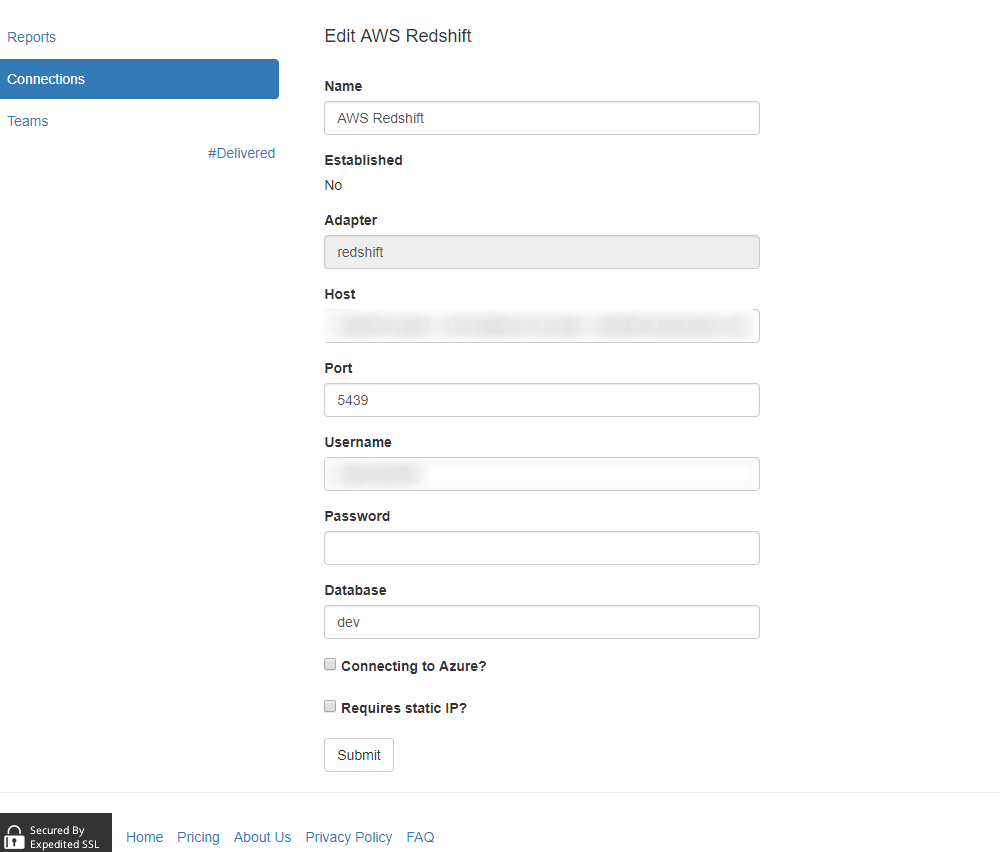
With that in place, we can create a simple report, and associate it with a Slack channel:
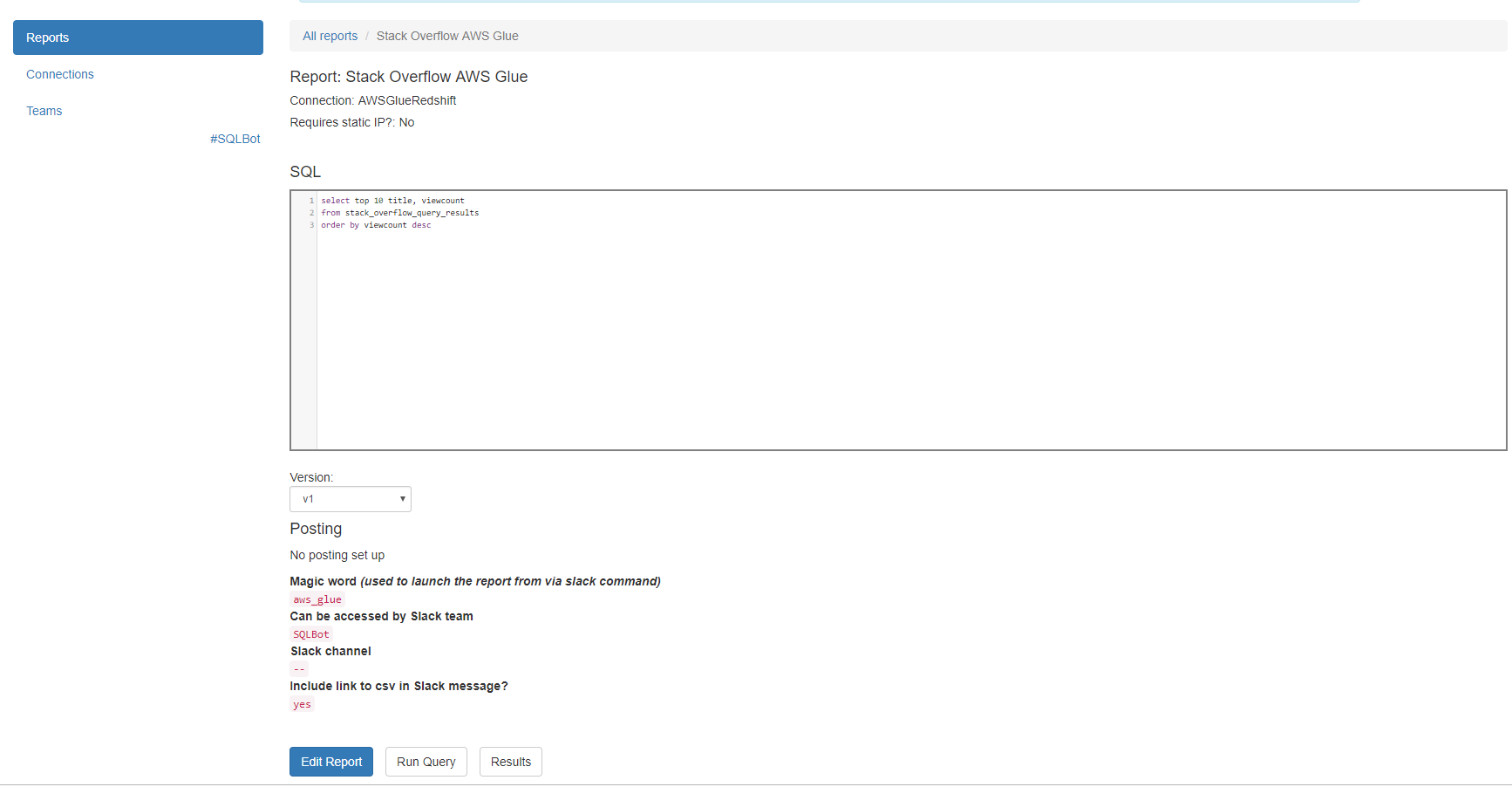
That is all that is required! With our report in place, we can execute, schedule, and view it in Slack:

In Conclusion
We've now got a working example of an ETL solution, and limitless potential to build upon it. While it labors, delivering results, let's take one last look at Frankenstein. There he sits, in his swamp, pondering the undergrowth. What must be running through his thick skull? One can only guess. Thankfully, his thoughts and tantrums are completely removed from your business. Let AWS Glue handle the ETL transformation. And leave the swamp storming, tree smashing duties to Frankenstein.
Need a simple way to get reports into Slack or email? Give SQLBot a try!