 By
By
Businesses are now responsible for managing more data than ever: at last count, an average of 163 terabytes (163,000 gigabytes). Organizations store much of this information in data warehouses: specialized data management systems that pull data from various sources and that
If you’ve been learning about data warehouses for your business, you might have run across the term “star schema.” What is a star schema
What is a Star Schema?

To define a star schema in data warehousing, we first need to go over some key database terms and concepts.
Star Schema: Terms and Concepts
There are two main types of data management systems: operational and reporting.
- Online transaction processing (OLTP) systems
are used for lightning-fast queries in response to live business processes. - Meanwhile, online analytical processing (OLAP) systems
are used for reporting and analytics, which allows for some sacrifices in performancein exchange for better insights and business intelligence.
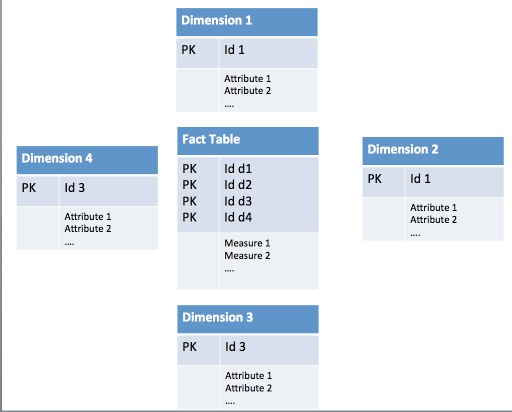
Data warehouses are OLAP systems, allowing users to access and analyze information from multiple sources simultaneously. Designing a data warehouse requires users to be familiar with the concept of dimensional modeling, which is an approach that optimizes the data warehouse for online queries. Dimensional modeling involves the concepts of fact tables and dimension tables.
A fact table will contain a grouping of related facts. For example, a fact table about customer purchases may include facts such as the number of purchases and the amount of each purchase. Because they contain numeric quantities,
Dimension tables
Fact tables and dimension tables frequently reference each other. A fact table usually contains
Now that we’ve established this crucial database terminology, let’s discuss how they apply to the concept of a star schema.
Star Schema: Definition
In database management systems, a schema is the structure of the database that describes how objects and information in the database are logically grouped and connected. A “star schema” gets its name from the fact that its diagram resembles a star, with various points radiating outward from the center.
As described above, there are two different
For example, suppose that we have a star schema for our data warehouse that stores customer order history. The fact table at the center of the star schema will contain data such as the product ID, customer ID, and price.
The price is a simple numerical quantity that will not
Why Do Businesses Use Star Schemas?
We’ve defined the concept of a star schema in the section above—so why would you want to use one for your data warehouse project?
Star schemas are the simplest and most widely used form of data warehouse schema, which makes them a good choice for data warehouses that
One thing to note about star schemas is that they are

Is a Star Schema Right for Your Data Warehouse?
For example, the geography dimension table in a star schema of moving companies may contain attributes representing
Star schemas are a highly popular choice for building data warehouses, but they’re
Snowflake schemas
This makes the snowflake schema a better choice than the star schema if you want your data warehouse schema to
Galaxy schemas, also known as “fact constellation schemas,” are complex data warehouse schemas that combine
Because they share dimension tables, using a galaxy schema can reduce the size of the data warehouse.
Final Thoughts
Star schemas are the simplest and most popular way of organizing information within a data warehouse. However, alternatives to the star schema, such as snowflake schemas and galaxy schemas, exist for users who will get more
Being able to get the right data-driven insights at the right time from your data warehouse is crucial. Whether you use a star schema for your data warehouse or a different model entirely,
Try SQLBot - It's Free!
Sign up for a free account on
About the Author
David Tidmarsh is a freelance software and technology writer and graduate student in computer science who specializes in artificial intelligence and big data. He's passionate about translating complex tech issues into clear, comprehensible language.