 By
By
Postgres LIKE Operator - 1 Tip To Make Your Query 80 Times Faster
I love SQL and I love Postgres. I've been playing around with the ~8 million unclaimed asset records in New York, and have been struggling with an efficient way to do a name search.
My problem is that the owner name on unclaimed property records comes through as one field, so if Homer Simpson had unclaimed money waiting for him, the official record could come through as a string like this:
SIMPSON HOMEROr like this:
HOMER SIMPSONIt gets even worse for business names, they get all messed up and can come through a bunch of different ways.
If the names came through in a predictable format, we could just use the LIKE command and have the first part of the string set, like this:
AND owner_name like 'SIMPSON%'
That query uses the index on owner_name efficiently, and comes back really quickly, here's the query plan:
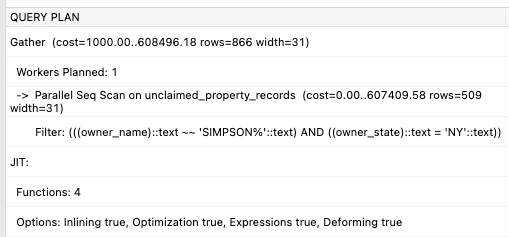
That query took 40 ms over 8M rows.
HOWEVER, since the data comes to us all jumbled, we have to do this with our LIKE statement:
AND owner_name like '%SIMPSON%'That totally hoses performance, since now Postgres can't use the index anymore because the leading % means that the database can't take advantage of the sorted nature of the B-tree index, as it has to scan for the substring at any position within the string. Booo!
Here's the query plan:
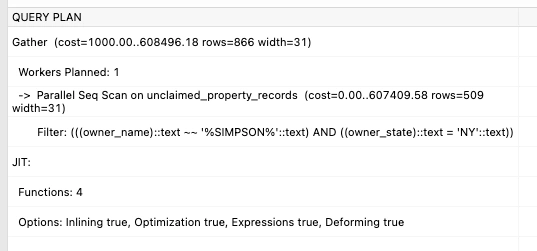
The query plan is the same, but since the database has to search through all records, it takes 3.2 seconds to come back, which is over 80 times slower!
Conclusion
WIth great power comes great responsibility. The LIKE operator is AWESOME. However, make sure you understand what how it's operating under the covers to make sure your queries sing instead of sleep.